新的大脑信息处理数学模型预测了一些视觉特性

人类的视网膜——眼睛的一部分,将入射光转换成电化学信号——有大约1亿个感光细胞。所以视网膜图像包含了大量的数据。高级视觉处理任务——比如物体识别、测量大小和距离,或者计算移动物体的轨迹——不可能保存所有这些数据:大脑没有足够的神经元。因此视觉科学家长期以来一直认为,大脑必须以某种方式总结视网膜图像的内容,在将它们传递到更高层次的过程之前减少它们的信息负荷。
1月27日,在光电仪器工程师学会的人类视觉和电子成像会议上,大脑和认知科学系的首席研究科学家Ruth Rosenholtz提出了一项新的数学模型大脑是如何进行总结的。该模型准确地预测了视觉系统在某些类型的图像处理任务中的失败,这很好地表明它捕捉到了人类认知的某些方面。
大多数人类模型对象识别假设大脑对视网膜图像做的第一件事是识别边缘——具有不同光反射特性的区域之间的边界——并根据排列顺序对它们进行排序:水平、垂直和对角线。然后,大脑开始将这些特征组合成原始的形状,例如,在视野的某个部分,一个水平的特征出现在一个垂直的特征之上,或者两条对角线互相交叉。从这些原始的形状,它建立了更复杂的形状-四个l例如,带有不同方向的物体会形成一个正方形,以此类推,直到它被构造成可以识别为已知物体特征的形状。
Rosenholtz认为,虽然这可能是一个很好的模型,说明在视野的中心发生了什么,但它可能不太适用于边缘,在那里人类对物体的辨别能力是出了名的弱。在过去几年的一系列论文中,Rosenholtz提出,认知科学家认为大脑是收集的统计数据关于视觉区域不同斑块的特征。
不完整的印象
在Rosenholtz的模型中,统计数据描述的斑块离中心越远,它们就越大。这与信息的损失相对应,从同样的意义上说,一个城市的平均收入所提供的信息少于该城市每个家庭的平均收入。在视野的中心,斑块可能非常小,以至于统计数字相当于对单个特征的描述:100%的水平特征集中可以表示单个水平特征。所以Rosenholtz的模型会收敛于标准模型。
但是在视野的边缘,这些模型是分开的。例如,一个统计数据为50%水平特征和50%垂直特征的大补丁可能包含一组十几个以上的符号,或者一组垂直和水平的线,或者一组方格。
事实上,Rosenholtz的模型包含的统计数据远不止特征的方向:还有特征大小、亮度和颜色,以及其他特征的平均值——总共大约1000个数字。但是在计算机模拟中,即使存储视野中每个区域的1000个统计数据,只需要存储视觉特征本身的虚拟神经元数量的1 / 90,这表明统计总结可能是大脑想要利用的节省空间的技术。
Rosenholtz的模型来源于她对一种叫做视觉拥挤的现象的研究。如果你把目光集中在一张几乎是空白的纸中间的一点上,你可能会在这页纸的左边边缘找到一个单独的a。但是你无法在右边缘找到一个相同的A,同样距离中心的距离,如果它不是自己站在单词“BOARD”的中心。
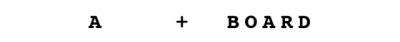
Rosenholtz的方法解释了这种差异:单个A的统计数据对A足够具体,大脑可以推断出字母的形状;但是在视野的另一边对应的斑块的统计数据也考虑到了B、O、R和D的特征,导致汇总的值不能清楚地识别出任何字母。
道路试验
Rosenholtz的小组还对人类进行了一系列实验,以测试模型的有效性。例如,受试者可能被要求在一堆干扰物中寻找一个目标物体——比如字母O——比如一堆其他字母。一小块视野包含11个Q和1个O的数据与包含12个Q的数据非常相似。但它的统计数据与包含十几个加号的补丁有很大不同。在实验中,不同patch的统计数据之间的差异程度是一个非常好的预测者可以多快找到目标物体:在正号中找到O比在Q中找到O要容易得多。
在计算机科学和人工智能实验室担任联合职务的Rosenholtz,也对她的工作对数据可视化的影响感兴趣,数据可视化本身就是一个活跃的研究领域。例如,设计地铁地图时,要最大限度地考虑不同地区汇总统计数据之间的差异,这样可以让匆忙的通勤者一眼就能看清楚。
纽约大学(New York University)心理学和神经科学教授丹尼斯·佩里(Denis Pelli)说,在视觉科学领域,“长期以来一直有这样一种观念,即视觉边缘在某种程度上是用来处理纹理的。”Rosenholtz的工作,他说,“是把它变成真实的计算,而不仅仅是一个旁注。”Pelli指出大脑可能并没有精确地跟踪Rosenholtz使用过的1000多个统计数据,事实上,Rosenholtz说她只是采用了一组通常用于描述计算机视觉研究中的视觉数据的统计数据。但是Pelli也补充说,像Rosenholtz正在进行的视觉实验是将列表缩小到“真正重要的”的正确方法。
进一步探索











用户评论