我们如何结合声音和表情?
人类社会相互作用是由我们承认人的能力。面孔和声音是已知的一些关键特性,使我们能够识别个人,他们有丰富的信息,如性别、年龄、体型,导致一个人独特的身份。大量的神经心理学和神经成像研究已经确定了不同大脑区域分别负责人脸识别和语音识别,但是我们的大脑是如何结合这两种不同类型的信息(视觉和听觉)仍然是未知的。
现在一项新的研究,发表在2011年3月爱思唯尔的问题皮质透露,大脑网络参与这个“跨通道”的人的认可。
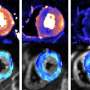
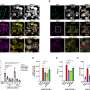
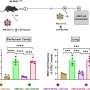
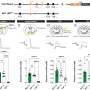
一组研究人员在比利时使用功能性磁共振成像(fMRI)来衡量大脑的活动在14个参与者在执行一个任务,他们承认以前学到的脸,声音,和voice-face协会。Frederic Joassin萨尔瓦多·坎帕内拉博士和他的同事们比较了脑区激活当承认人们从他们使用的信息脸(视觉区域),或者只有他们的声音(听觉区域),这些激活当使用组合信息。他们发现voice-face识别激活特定的“跨通道”的大脑区域,位于区域称为左角回和正确的海马。进一步分析也证实正确的海马体是连接到不同的视觉和听觉的大脑区域。
承认一个人从自己的脸和声音的结合信息因此不仅依赖于相同的大脑网络参与只使用视觉或听觉信息,但也在大脑区域与注意力相关(左角回)和内存(海马)。根据作者,发现支持的跨通道的动态视觉交互领域参与处理的脸和声音信息不仅仅是一个层次模型的最后阶段,而是,他们可能并行工作和相互影响。
更多信息:这篇文章是“跨通道之间的交互人类参与的人的面孔和声音识别”的Frederic Joassin毛罗·Pesenti,皮埃尔•Maurage艾米莉Verreckt,雷蒙德•Bruyer萨尔瓦多·坎帕内拉,出现在皮质,体积47岁的问题3(2011年3月)。http://www.sciencedirect.com/science/journal/00109452