新的流行病学模型结合了多种基因组数据

仅仅像“个性化医学”和“大数据”这样的流行语和“大数据”之间的差异是在开发分析和解释基因组数据的方法的细节中。在一对新论文中,棕色大学流行病学家日元黄和同事们展示了整合不同种类的基因组数据可以改善基因和疾病之间关联的研究。
Huang的种类是DNA的单核苷酸差异,称为SNP,基因表达数据,这是体内将基因的作用和甲基化含有与表达相关的化学改变。所有人都可能与一个人是否生病相关,而是大多数分析,只有一个人将基因组学结合到疾病。在现在的论文中在期刊上生物统计学和应用统计数据,黄描述了在哮喘分析中测试模型的结果脑癌数据。
“我们的综合方法优于单平台方法,”黄说。“应用于真实数据集,它有效。”
提高性能
统计模型黄色与塔尔·Vanderweele和哈佛大学的西红林开发,共同作者,并不纯粹统计。其结构和假设是由潜在的生物学通知。SNP可以与疾病直接相关,或者可以通过基因,包括SNP所在的基因介导的协会在健康或病人的病人中表达。
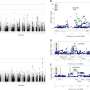
这篇年报文章详细描述了带有SNPs和表达的模型,以及它在连接ORMDL3基因与哮喘的数据上的应用。使用这个模型,作者在与疾病有显著关联的基因中发现了15个SNPs,相比之下,只有5个明显地单独分析SNPs。研究人员还发现,与跟踪一个变量或试图混合多个数据集的传统方法相比,他们的“p值”(一种衡量关联统计显著性的方法)实质上更低,因此更强,当使用他们的模型允许的组合分析时。
他们知道该模型不太可能只是搅拌很多错误的SNP,因为它们也将其测试它反对“空”数据,在那里它不应该找到任何东西,而且事实上它没有。
与不同的科目有效
Huang进一步扩展了模型,再次报告了类似的结果生物统计学- 在哮喘数据集中的新潜在相关基因和较低的P值以及涉及基因GRB10和胶质母细胞瘤多形态脑肿瘤的基因。但本文提供了额外的贡献。其中一个是表明,即使SNP数据和SNP数据也是有用的基因表达数据来自不同的人,只要受试者通常是可比的。另一个是它不仅整合了SNP和表达,还集成了DNA甲基化数据,这是一个化学改变与表达相关的DNA。
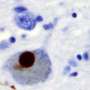
这很重要,因为基因表达DNA甲基化可以是组织依赖性的。在脑癌的情况下,流行病学家很少可符合从相同的受试者中检索脑组织,从他们可以更容易易于样本DNA。
在一项新的研究中,黄将与棕色流行病学同事进行多米尼克·米科··米科德进行,他计划将模型应用于新的脑癌数据,包括来自患有和没有肿瘤的受试者的DNA以及来自死亡的人组织的表达数据脑癌或其他原因。
可能还有许多其他应用程序。他补充说,模型的两个变量(可能调节另一个)和结果的常规结构,允许它应用于类似结构化的现象,而不仅仅是基因组学和疾病。
“我认为我们的方法代表了一个新的数据集成框架,”黄说。“只要你能在这种调解方面阐述你的生物问题模型,然后我们的方法可以帮助您轻松分析您的数据。“
进一步探索








用户评论