洞察人类大脑是如何解决复杂的决策问题
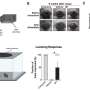
 Computational model of human prefrontal meta reinforcement learning (left) and the brain areas whose neural activity patterns are explained by the latent variables of the model. (B) Examples of behavioral profiles. Shown on the left is choice bias for different goal types and on the right is choice optimality for task complexity and uncertainty. (C) Parameter recoverability analysis. Compared are the effect of task uncertainty (left) and task complexity (right) on choice optimality. Credit: The Korea Advanced Institute of Science and Technology (KAIST)")
一项新的研究在元强化学习算法帮助我们理解人类大脑学会如何适应复杂性和不确定性,当学习和决策。为首的一个研究小组唱Wan李教授韩科院会同约翰奥多尔蒂在加州理工学院,成功地发现了一个人类元强化学习计算和神经机制,开放的可能性移植人类智慧为人工智能算法的关键元素。这项研究提供了一个了解如何最终使用计算模型逆向工程人工强化学习。
这项工作发表在12月16日,2019年的《华尔街日报》自然通讯。这篇论文的题目是“任务复杂性与基于模型之间的仲裁中状态空间不确定性和模范自由学习。”
人类强化学习是一种固有的复杂的和动态的过程,包括目标设定、战略的选择,选择动作,认知资源分配策略修改,等等。这是一个非常具有挑战性的问题对人类解决由于快速变化和multifaced操作环境中人类。更糟的是,人类经常需要迅速重要的决定之前得到的机会收集大量的信息,不同的情况下使用深度学习方法在人工智能应用程序模型学习和决策。
为了解决这个问题,该研究小组使用一种叫做“强化学习理论基础实验设计”的技术来优化两级三个变量的马尔可夫决策此项任务,任务的复杂性、不确定性和任务。这种实验设计技术允许团队不仅控制混杂因素,但也创造一个类似的情况发生在人类实际解决问题。
其次,该团队使用一个名为“基于模型的神经影像学的技术分析。基于获得的行为和功能磁共振成像数据,超过100个不同类型的元强化学习算法找到一个互相对抗计算模型这可以解释行为和神经数据。第三,为了一个更严格的验证,研究小组应用一个叫做‘复苏参数分析,分析方法包括高精度两人体行为分析和计算模型。
通过这种方式,团队能够准确地识别元强化学习的计算模型,不仅确保模型的明显的行为类似于人类的,而且该模型解决问题以同样的方式作为人类做的。
研究小组发现,人们倾向于增加规划进行强化学习(称为基于模型的控制),为了增加任务的复杂性。然而,他们采取一个更简单、更资源有效的策略被称为模范自由控制,当不确定性和任务的复杂性都高。这表明这两个任务的不确定性和复杂性在元交互控制的强化学习。计算功能磁共振成像分析表明任务复杂性与神经表征学习策略的可靠性的劣质前额叶皮层。
这些发现显著进步的理解的性质计算实施下前额叶皮层在元强化学习以及洞悉更一般的大脑如何解决问题的不确定性和复杂性在动态变化的环境。识别关键计算变量间的前额叶元强化学习,也可以通知的了解这一过程可能会容易分解在某些精神疾病,如抑郁症和强迫症。此外,获得了计算的了解这一过程有时会导致模范自由控制,可以提供深入了解在某些情况下任务性能高认知负荷的条件下会分解。
李教授说,“这项研究将巨大的感兴趣的研究人员在人工智能与人类/计算机交互领域因为这个拥有巨大潜力应用核心见解收集人类智能与人工智能算法如何。”
更多信息:Dongjae Kim等任务的复杂性与基于模型之间的仲裁中状态空间不确定性和模范自由学习,自然通讯(2019)。DOI: 10.1038 / s41467 - 019 - 13632 - 1