新的深度学习方法使糖尿病相关眼病的临床自动筛查成为可能

Helmholtz Zentrum München的研究人员与LMU大学慕尼黑眼科医院和慕尼黑工业大学(TUM)一起创造了一种新的深度学习方法,使糖尿病视网膜病变等眼病的自动筛查更有效。该方法减少了训练算法所需的昂贵注释图像数据量,对临床有吸引力。在糖尿病视网膜病变的案例中,研究人员开发了一种筛选算法,需要的注释数据减少75%,并实现了与人类专家相同的诊断性能。
近年来,诊所已经向人工智能和深度学习迈出了第一步,以实现医疗筛查的自动化。然而,训练是一种深度学习算法为了进行准确的筛查和诊断,预测需要大量的注释数据,而诊所往往需要昂贵的专家标签。因此,研究人员正在寻找方法,以减少对昂贵的注释数据的需求,同时仍然保持算法的高性能。
用例糖尿病性视网膜病变
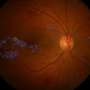
糖尿病性视网膜病是一种与糖尿病相关的眼病,会损害视网膜,最终导致失明。视网膜厚度的测量是高危患者诊断疾病的重要步骤。为了做到这一点,大多数诊所会拍摄眼底——眼睛后部的表面。为了自动化筛选这些图像,诊所开始应用深度学习算法。这些算法需要大量带有昂贵注释的眼底图像,以便训练出正确的屏幕。
慕尼黑LMU大学眼科医院拥有超过12万张未注释眼底和共同注册OCT图像的人群规模数据集。光学相干断层扫描(OCT)可以获得视网膜厚度的精确信息,但并不是每个眼科保健中心都能获得。LMU将他们的数据提供给了Helmholtz Zentrum München公司的研究人员,该公司是人工智能健康领域的先驱。
训练的“慎独”下
Helmholtz Zentrum München和TUM生命科学学院的研究第一作者Olle Holmberg说:“我们的目标是利用这一独特的大眼底和OCT图像来开发一种方法,将减少对昂贵的带标注数据的算法训练的需求。”
这组研究人员开发了一种名为“交叉模式自监督视网膜厚度预测”的新方法,并将其应用于使用LMU数据集预先训练深度学习算法。在这个用例中,交叉模式自我监督学习允许算法自学识别带有不同oct提取的视网膜厚度轮廓的无注释眼底图像,直接从眼底预测厚度信息。通过准确预测视网膜厚度(糖尿病视网膜病变的关键诊断特征),该算法能够学习如何预测筛查结果。
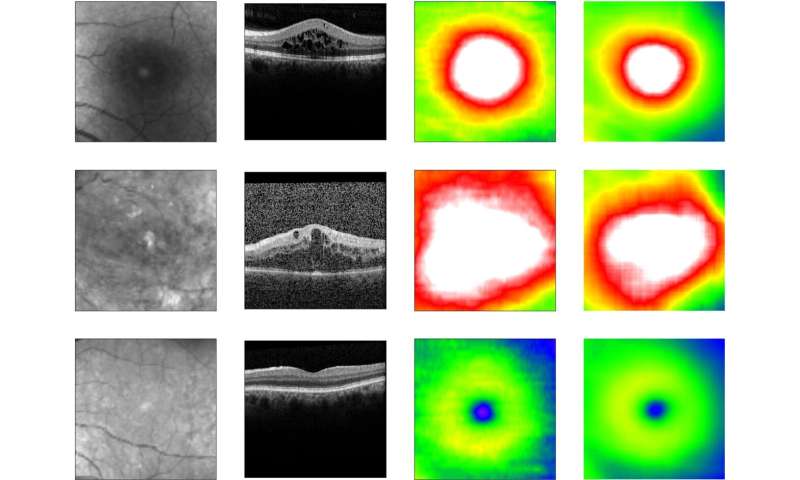
使用四分之一的训练数据实现高性能
这种新的方法减少了对昂贵的注释数据进行训练的需要深度学习算法显著。当应用于糖尿病视网膜病变的自动筛查时,与需要更多训练数据的以前的算法和人类专家相比,它实现了相同的诊断性能。
“我们减少了75%对带标注数据的需求,”Fabian Theis教授说,他是亥姆霍兹中心München计算生物学研究所主任和亥姆霍兹协会人工智能平台亥姆霍兹人工智能科学主任。“稀疏注释数据是医学领域的一大挑战。我们的目标之一是开发使用更少数据的方法,然后潜在地应用于许多环境中。我们在糖尿病视网膜病变上的应用案例可以立即用于诊所,这是人工智能如何改善诊所日常业务,从而改善每个人的健康的一个完美例子。”
“视力受损糖尿病的自动检测和诊断视网膜病变随着眼底摄影技术的广泛应用,这对筛查来说是一个很大的改进。病人转介到部分过于拥挤的专业眼科护理中心的情况也可以减少,”慕尼黑大学眼科医院的Karsten Kortuem博士说,他负责这项研究的临床方面。
此外,在规模上的一个额外的减少,意味着参数的数量,实现了算法本身。这种新方法可以实现200倍的小算法。这可能是将它们部署在移动和嵌入式设备上的一个至关重要的好处,这在临床环境中也很重要。
应用范围超越糖尿病视网膜病变
除了糖尿病性视网膜病变,这种新方法可以用于更多的临床应用,其中有很多未注释的数据,但缺乏专家注释,如年龄相关性黄斑变性(AMD)。
进一步探索













用户评论