新算法将防止癌细胞的误识别

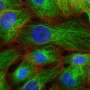
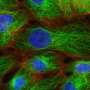
肯特大学的研究人员开发了一种计算机算法,可以基于微观图像识别癌细胞系的差异,这是在实验室中结束细胞误诊的独特发展。
癌症细胞系是孤立和生长的细胞细胞培养物在实验室研究和发展抗癌药物。然而,许多细胞系在随他人换下或被他人污染后被错误识别,这意味着许多研究人员可以使用不正确的细胞。
这一直是持续存在的问题癌细胞系开始了。短串联重复(str)分析通常用于鉴定癌细胞系,但昂贵且耗时。此外,Str不能区分来自同一个人或动物的细胞。
基于微观图像来自一系列细胞系和利用能够“深入学习的计算机模型”,肯特的工程和数字艺术学院(EDA)和计算学院(SOC)的研究人员通过癌细胞数据的质量比较培训了计算机。从此,它们开发了一种允许计算机检查细胞系的单独微观数字图像的算法,并准确地识别和标记它们。
这种突破有可能提供易于使用的工具,可以快速识别实验室中的所有细胞系,而没有专家的设备和知识。
这项研究由Chee(Jim)Ang(SoC)和Gianluca Marcelli博士(EDA)领导,带有领先的癌症细胞系专家Martin Michaelis教授和Mark Wass博士(Biosciences学院)。
多媒体/数字系统的高级讲师Ang博士表示,“我们的合作表明了实验室和癌症研究中的潜在未来实施的巨大结果。利用这种新算法将产生进一步的结果,可以进一步改变科学中细胞识别格式的结果,给研究人员更好地有机会正确识别细胞,导致癌症研究中的误差和潜在的节约生命。
“结果还表明,计算机模型可以正确地分配用于识别细胞系的精确标准,这意味着未来研究人员在准确地识别细胞中培训的可能性也可以大大提高。”
进一步探索
更多信息:Deogratias Mzurikwao等,朝着使用深神经网络的基于图像的癌细胞系认证,科学报告(2020)。DOI:10.1038 / S41598-020-76670-6
信息信息:
科学报告
由...提供肯特大学
引文:新算法将防止癌细胞的错误识别(2020,12010)从HTTPS://medicalXpress.com/news/2020-12-algorithm-misidentification-cancer-cells.html中检索2021年5月20日2021年5月20日
本文件受版权保护。除了私人学习或研究目的的任何公平交易外,没有书面许可,没有任何部分。内容仅供参考。










用户评论