一种计算方法来理解婴儿如何感知语言

语言在他们使用的声音上有所不同。例如,日语不会像“摇滚”与“锁”中的“ r”和“ l”声音区分。值得注意的是,婴儿在学会说话之前就开始对母语的声音进行调整。例如,一岁的婴儿在说日语而不是英语的环境中,不太容易区分“岩石”和“锁”。
对这种早期语音学习现象的有影响力的科学说明最初提出,婴儿组通过称为分布学习的统计聚类机制向天然元音和类似辅音的语音类别听起来。
然而,本周发表在本周发表的一项新研究挑战了婴儿学习辅音和元音的语音类别的想法。美国国家科学院论文集。
在这项研究中,认知科学家和计算语言学家的多机构团队引入了定量建模框架,该框架基于对大规模的模拟语婴儿的学习过程。使用计算高效的机器学习技术,这种方法可以系统地将学习机制与有关婴儿对母语的调整的可检验预测进行系统链接。
“假设什么传统上是由婴儿学习的,传统上驱动了研究人员了解这种令人惊讶的现象的尝试,”马里兰州马里兰州高级计算机研究学院(UMIACS)的博士后学会托马斯·沙茨(Thomas Schatz)说,他是该研究的主要作者。”我们。提议从关于关于的假设如何婴儿可能会学习。”
除Schatz外,该研究的作者还包括马里兰州大学语言学副教授Naomi Feldman,并任命UMIACS。莎朗·戈德沃特(Sharon Goldwater),爱丁堡大学信息学院语言,认知和计算研究所教授;Xuân-nga Cao是巴黎Ecole NormaleSupérieure(ENS)的研究工程师,Langinnov和Gazouyi创业公司的联合创始人;以及ENS认知机器学习团队的教授Emmanuel Dupoux。
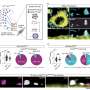
在他们的研究中,研究人员通过训练对现实语音输入的计算有效的聚类算法来模拟婴儿的学习过程。该算法是按照定期时间间隔采样的类似频谱图样的听觉功能,这些功能是从目标语言中获得的自然主义语音记录获得的。在这项研究中,美国英语和日语是使用的两种语言。
研究人员说,这产生了一个早期的语音知识的候选模型。接下来,他们问了训练有素的模型的两个问题。他们能解释观察到的日语和英语学习婴儿如何歧视语音的差异吗?而且,模型是否学习了元音和辅音样语音类别?
早期语音学习的主要科学说明将期望这些问题的答案匹配(两者都应该是“是”,或者两者都应该是“否”)。研究人员发现,第一个问题的答案是积极的:他们的模型确实说明了婴儿观察到的行为,尤其是日本婴儿的难度,而诸如“摇滚”和“锁”之类的词。然而,第二个问题的答案是负面的:发现模型学到的语音单元太简短且声学上可变,无法与元音和辅音样语音类别相对应。
这些结果表明,关于早期语音学习的现有文献进行了惊人的重新解释。将语音类别的分布学习扩展到现实的学习条件上的困难可能会更好地解释为质疑这样的想法什么婴儿学习是语音类别,而不是如何婴儿学习是通过纯粹的分布学习(传统解释)。
Schatz说,认知科学并不传统上使用如此大规模的建模,但是计算能力,大数据集和机器学习算法的最新进展使得这种方法比以往任何时候都更可行。
Schatz和Feldman是UMIACS的计算语言学和信息游行(CLIP)实验室的一部分,费尔德曼(Feldman)是现任董事。费尔德曼说,剪辑实验室和巴黎认知机器学习实验室中的强大计算资源对研究项目起了重要作用。
总之,研究人员认为,他们基于计算的建模方法 - 与该领域的持续努力大规模收集经验数据,例如家庭中婴儿学习环境的大规模记录以及对婴儿学习成果 - 为对早期语言获取的更深入了解的道路开辟了道路。
进一步探索