科学家们展示了生物信息学用质粒曲目的益处

跟踪综合遗传密码的起源从未简单,但可以通过生物信息或越来越多的深度学习计算方法来完成。
尽管后者获得了最大的关注,但莱斯大学布朗工程学院的计算机科学家托德·特里根的新研究关注的是序列比对和基于全基因组的方法是否能优于目前的方法深度学习该地区的方法。
“这是一个有道理的是,鉴于谷物,鉴于这种深入学习方法最近表现出爆炸等传统方法,”他说。“我与这项研究的目标是开始对谈话如何结合两个域的专业知识来实现这一重要的计算挑战的进一步改进。”
专门为生物安全和微生物法医学应用开发计算解决方案的Treangen和他在赖斯大学的团队引进了PlasmidHawk,这是一种生物信息学方法,通过分析DNA序列来帮助确定感兴趣的工程质粒的来源。
他说:“我们证明了基于序列比对的方法在实验室起源预测的特定任务中比卷积神经网络(CNN)深度学习方法表现更好。”
由Treangen领导的研究人员和Rice的研究生、第一作者Qi Wang在一篇开放获取的论文中报告了他们的结果自然通讯。
开源软件可在此处提供:gitlab.com/treangenlab/plasmidhawk。
该程序不仅可以用于跟踪潜在有害的工程序列,还可用于保护知识产权。
“目标要么有助于保护序列贡献者的知识产权,或者如果确实发生了糟糕的事情,有助于追踪合成序列的起源,”Treangen说。
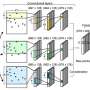
Treangen注意到最近一篇高调的论文描述了一种循环神经网络(RNN)深度学习技术来追踪序列的起源实验室。该方法对单个实验室的预测准确率达到70%。他说:“尽管与之前的深度学习方法相比有了重要的进步,但与两种方法相比,PlasmidHawk提供了更好的性能。”
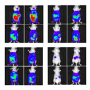
稻米计划从基因组数据集直接对齐未知的代码字符串,并将它们与合成生物研究实验室常见或独特的泛基因组区域匹配
“为了预测原产地,基于未分类序列和质粒泛基因组之间的匹配区域,PlasmidHawk评分每个实验室,然后将未知序列分配给具有最小分数的实验室,”王说。
在新的研究中,使用与深层学习实验相同的数据集,研究人员报告了“未知序列”存款实验室的成功预测“76%的时间。他们发现,正确的实验室的85%的时间是前10名候选人。
他们说,与深度学习方法不同的是,PlasmidHawk需要减少数据预处理,并且在现有项目中添加新序列时不需要再训练。与之前的深度学习方法相比,它还提供了一个详细的解释,解释其实验室起源的预测。
“我们的目标是用尽可能多的工具填充你的计算工具箱,”合著者Ryan Leo Elworth说,他是赖斯大学的博士后研究员。“最终,我相信最好的结果将结合机器学习、更传统的计算技术和对你正在解决的特定生物学问题的深刻理解。”
莱斯大学的研究生Bryce Kille和Tian Rui Liu是这篇论文的共同作者。特里根是计算机科学的助理教授。
该研究得到了国家卫生研究院通过国家智能和军队研究办公室的国家疾病和中风研究所支持。addgene提供了对沉积质粒的DNA序列的进入。
进一步探索
Ethan C. Alley等。用于基因工程署的机器学习工具包,以方便生物安全,自然通讯(2020)。DOI:10.1038 / S41467-020-19612-0














用户评论