超过突变的总和:在机器学习的帮助下确定了165个新的癌症基因

一种新的算法可以预测哪种基因导致癌症,即使它们的DNA序列没有改变。柏林研究人员组合了各种各样的数据,用“人工智能”分析并确定了许多癌症基因。这为个性化药物和生物标志物的发展开辟了针对靶向癌症治疗的新视角。
在癌症中,细胞失去控制。它们激增并将其途径推入组织,破坏器官,从而损害必要的重要功能。这种不受限制的生长通常是通过癌症基因的DNA变化的积累来诱导。这些基因中的突变,用于治理细胞的发育。但有些癌症只有很少的突变基因,这意味着其他原因在这些病例中导致疾病。
柏林最大普朗克分子遗传学研究所(MPIMG)和赫尔默尔兹ZentrumMünchen计算生物学研究所的一组研究人员。新算法采用机器学习技术鉴定165个以前未知的癌症基因。这些基因的序列不一定改变 - 显然,这些基因的失调可能导致癌症。所有新鉴定的基因都与众所周知的癌症基因密切合作,并且已被证明对于细胞培养实验中肿瘤细胞的存活至关重要。
个性化药物的额外目标
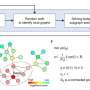
该算法,被称为“emogi”,用于解释的多OMICS图集成,也可以解释细胞机械中的关系,使得一个基因a癌症基因。作为由Annalisa Marsico领导的研究人员在期刊中描述自然机器智力,软件集成了数万数据集从患者样品产生。这些含有关于DNA甲基化的信息,除了具有突变的序列数据之外还包含细胞途径中的单个基因的活性和蛋白质的相互作用。在这些数据中,一个深度学习算法检测导致癌症发育的模式和分子原理。
“理想情况下,我们在某些时候全面了解所有癌症基因的全部癌症基因,这可能对不同患者的癌症进展产生不同的影响”,MPIMG的研究组负责人Marsico表示,直到最近,现在在HelmholtzZentrumMünchen。“这是个性化的基础癌症治疗。“
与常规癌症治疗不同,如化疗,个性化治疗恰好均匀地治疗肿瘤的类型。“目标是为每位患者选择最佳疗法 - 也就是说,最有效的治疗方法,副作用最少。此外,我们将能够根据其分子特征来识别早期阶段的癌症。”
“只有我们知道疾病的原因,我们将能够有效地抵消或纠正它们,”研究人员说。“这就是为什么识别尽可能多的机制如此重要,可以诱导癌症。”
通过组合更好的结果
“到目前为止,大多数研究都集中于遗传序列的致病变化,即在细胞的蓝图中,”Marsico团队的博士生和出版物第一作者的博士生。“与此同时,近年来它变得明显,表述扰动或失调的基因活性也会导致癌症。”
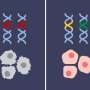
这就是研究人员合并了在蓝图中反映故障的序列数据的原因,其中包含表示单元格中的事件的信息。最初,科学家们证实了这种突变,或基因组的段的繁殖,确实是癌症的主要驱动因素。然后,在第二步骤中,它们针对实际癌症驾驶基因的直接上下文处分为基因候选。
“例如,我们发现其序列在癌症中大部分不变的基因,并且对于肿瘤是必不可少的,因为它们规范能源供应,”Schulte-Sasse说。这些基因通过其他方式与其他方式失控,例如。由于DNA等化学变化如甲基化。这些修改将序列信息完整留下,但控制基因的活动。“这些基因是有前途的药物目标,但由于它们在后台运行,我们只能通过使用复杂的算法找到它们。”
寻找进一步研究的提示
研究人员的新计划为近年来700到1,000的疑似癌症基因列表增加了相当数量的新条目。只有通过生物信息学分析的组合和最新的人工智能(AI)方法,研究人员能够追踪隐藏基因。
“蛋白质和基因的相互作用可以被映射为数学网络,称为图表,”Schulte-Sasse说。“你可以想到它就像试图猜测铁路网络;每个站对应于蛋白质或基因,它们之间的每个相互作用是列车连接。”
在深度学习的帮助下 - 有帮助的非常算法人工智能近年来取得突破 - 研究人员能够发现甚至那些先前没有注意到的火车连接。Schulte-Sasse有计算机分析来自16种不同癌症类型的数万种不同的网络地图,每个数据点均含有12,000至19,000个数据点。
适用于其他类型的疾病
隐藏在数据中是更有趣的细节。“我们看到依赖于特定癌症和组织的模式”Marsico说。“我们认为这是肿瘤通过不同器官的不同分子机制引发的证据。”
Emogi计划不仅限于癌症,研究人员强调。理论上,它可以用于整合各种生物数据并在那里找到模式,解释了Marsico。“应用我们的算法对于应用多方面数据以及在其中的地方来说是有用的基因扮演一个重要角色。一个例子可能是复杂的代谢疾病,如糖尿病。“
进一步探索













用户评论