新冠病毒雷达:基因测序可以帮助预测下一个变种的严重程度
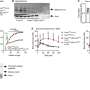
 Mean clinical severity over time for patients in different age groups, showing that the overall trends are generally consistent across age groups, with older patients having mean severity as shown in Panel A. (B – Middle) Mean clinical severity, separating male and female samples, showing consistent trends across gender with male patients generally having a somewhat higher ratio of severe cases. (C - Right) Number of mild and severe cases across all samples split by gender, showing that there are more mild cases than severe among samples from female patients. Credit: <i>Computers in Biology and Medicine</i> (2022). DOI: 10.1016/j.compbiomed.2022.105969")
在世界各地的公共卫生官员应对最新一轮COVID-19大流行的时候,德雷塞尔大学的研究人员创建了一个计算机模型,可以帮助他们更好地为下一次大流行做准备。该模型使用机器学习算法,经过训练可识别COVID-19病毒遗传序列变化与传播、住院和死亡人数上升之间的相关性,可就新变体的严重程度提供早期预警。
这场大流行已经持续了两年多,科学家和公共卫生官员正在尽最大努力预测SARS-CoV-2病毒的突变可能如何使其更具传染性、避开免疫系统并可能导致严重感染。但是收集和分析基因数据识别新的变异,并将其与感染该病毒的特定患者联系起来,仍然是一个艰巨的过程。
正因为如此,大多数关于新的“担忧的变种”(世界卫生组织将其分类)的公共卫生预测都是基于对它们已经传播的地区的监测测试和观察。
“像omicron这样的新变种在全球传播的速度意味着,当公共卫生官员很好地了解他们的人群可能有多脆弱时,病毒已经到来了,”德雷塞尔大学工程学院的助理研究教授、领导该研究的bahad a . Sokhansanj博士说计算机模型.“我们正试图为他们提供一个早期预警系统,就像气象学家的高级天气模型一样,这样他们就可以快速预测一种新的变体很可能是这样的——因此要做好相应的准备。”
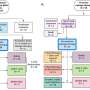
Drexel模型,最近发表在杂志上生物与医学中的计算机该方法是通过对病毒刺突蛋白基因序列的有针对性的分析来实现的,刺突蛋白是病毒的一部分,可以让病毒躲过病毒免疫系统并感染健康的细胞结合对COVID - 19患者的年龄、性别和地理位置等因素的混合效应机器学习分析,它也是在大流行期间已知突变最频繁的部分。
学会寻找模式
该研究团队使用了一种名为GPBoost的新开发的机器学习算法,该算法基于大公司分析销售数据的常用方法。通过文本分析,程序可以快速锁定基因序列中最有可能与变异严重性变化相关的区域。
它将这些模式与从患者元数据(年龄和性别)和医疗结果(轻症、住院、死亡)中收集的数据分层。该算法还考虑到,并试图消除由于不同国家收集数据的方式而产生的偏差。这个训练过程不仅允许程序验证它已经对现有的变体做出的预测,而且它还使模型做好准备,以便在遇到刺突蛋白的新突变时进行预测。它根据患者的年龄或性别将这些预测显示为一系列严重程度——从轻微病例到住院和死亡。
“当我们得到一个序列时,我们就可以在实验室用动物模型或细胞培养进行实验之前,或者在足够多的人生病之前,就可以收集流行病学数据,对一个变体的严重疾病的风险进行预测。换句话说,我们的模型更像是一个出现变种的早期预警系统。”Sokhansanj说。
来自GISAID数据库的遗传和患者数据——关于感染冠状病毒的人的最大信息汇编——被用于训练算法。一旦这些算法准备就绪,研究小组就用它们对ba后的小粒亚变异进行预测。1和BA.2。
Sokhansanj说:“我们表明,未来的omicron亚变异更有可能导致更严重的疾病。”“当然,在现实世界中,这种加重的疾病严重程度将被先前的omicron变体先前的感染所缓解——这个因素也反映在建模中。”
跟上新冠疫情
德崇信对COVID-19预测建模的定向方法是一项至关重要的发展,因为正在收集的大量基因测序数据使标准分析方法难以快速提取有用信息,以跟上病毒的新突变。
”的数量峰值蛋白质德雷塞尔大学生态和进化信号处理与信息学实验室主任、工程学院教授盖尔·罗森博士说:“病毒已经发生了相当大的突变,而且很可能会继续,因为病毒遇到了以前从未感染过的宿主。”
她说:“一些估计表明,SARS-CoV-2只‘探索’了30-40%的潜在刺突突变空间。”“当你考虑到每个突变都可能影响病毒的关键特性,如毒性和免疫逃避时,能够快速识别这些变异并理解它们对那些易受感染的人意味着什么似乎至关重要。”
罗森的实验室一直走在使用算法去除基因测序数据噪音和识别可能重要的模式的前沿。在大流行早期,该小组能够通过开发一种快速识别和标记其突变的方法来跟踪新SARS-CoV-2变体的地理演变。她的团队继续利用这一过程,以更好地了解这一流行病的模式。
视觉变量之间的
到目前为止,科学家们主要是通过实验室实验和流行病学研究,利用基因测序更好地识别突变。在将特定的基因序列变异与新变异的病毒传播性联系起来方面鲜有成功。德雷塞尔大学的研究人员认为,这是由于随着时间的推移,疫苗接种和免疫的逐步变化,以及不同国家报告数据的方式不同。
“我们知道,到目前为止,每一个连续的COVID-19变体都导致了轻微的感染,因为疫苗接种、免疫力和卫生保健提供者对如何治疗感染有了更好的了解。但我们通过混合效应分析发现,这一趋势并不一定适用于每个国家。这就是为什么我们的模型将地理位置作为机器学习算法考虑的变量之一,”Sokhansanj说。
虽然病人和公共卫生数据的差异和不一致一直是一个挑战公共卫生官员在整个大流行期间,德雷克塞尔模型能够解释这一点,并解释它是如何影响算法的预测的。
Sokhansanj说:“我们的关键目标之一是确保该模型是可解释的,也就是说,我们可以知道它为什么会做出这样的预测。”“你真的想要一个模型,它能让你深入了解,例如,它的预测可能与生物学家从实验室实验中理解的结果相一致或不一致的原因,以确保预测建立在正确的结构上。”
一个更好的观点
研究小组指出,这类进展强调了向世界脆弱地区提供更多公共卫生资源的必要性——不仅用于治疗和疫苗接种,还用于收集公共卫生数据,包括对新出现的变种进行测序。
研究人员目前正在使用该模型更严格地分析当前的一组新出现的变种,这些变种将在omicron BA.4和BA.5之后成为主导。
Sokhansanj说:“这种病毒可以,也将继续让我们感到惊讶。”“我们迫切需要扩大我们在全球范围内对变种进行测序的能力,这样我们就可以在潜在危险的变种出现时立即分析它们的序列——在它们成为全球问题之前。”