研究人员使用全基因组测序扩展和升级1000基因组计划资源
")
7年前,1000基因组计划(1kGP)发布了一个开放获取的资源,其主要基于低覆盖率的全基因组测序(WGS)数据,来自代表世界5个大陆地区的26个种群的2504个个体,这是WGS首次大规模提供人类遗传变异目录。
现在,纽约基因组中心(NYGC)的研究人员与麻省总医院、耶鲁大学和人类基因组结构变异联盟(HGSVC)的团队合作,已经扩展了1kGP资源,包括几乎所有的亲子三联系,以及原始样本,并使用Illumina NovaSeq仪器在高覆盖率上对它们进行测序。这项研究发表在细胞,对扩大的1kGP队列的高覆盖率WGS数据进行了全面分析,该队列目前包含3202个样本,包括602个三联组。
“1000基因组计划队列是如此宝贵的资源,我们认为它将对社区有用,使测序与最新版本的短读技术,同时增加之前省略的家族样本的丰富程度,”Michael Zody博士解释说,他是NYGC计算生物学的科学主任,也是该研究的高级作者。
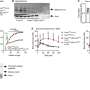
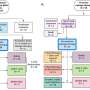
利用最先进的方法和算法,NYGC的研究人员对来自淋巴母细胞系(LCLs;即,来自外周血的不朽人类B细胞)从扩展队列的目标深度达到30倍基因组覆盖。接下来,研究小组进行单核苷酸测序变体(SNV)和短插入和删除(INDEL)调用,其中包括从序列数据中相对识别出不同的位点人类基因组在队列中所有样本中发现的变异位点的参考和基因分型。
此外,来自哈佛医学院、Broad研究所和麻省总医院的Michael Talkowski博士团队,与耶鲁大学和华盛顿大学医学院的Ira Hall博士团队以及HGSVC合作,通过整合多种分析方法,在3202个1kGP样本中发现了一组全面的结构变异(sv),并对其进行了基因分型。
总体而言,该研究表明,变异调用的发现能力和精度都有了显著提高,特别是在罕见的snv、indel和sv跨越频谱的情况下,这是以前低覆盖率测序无法达到的。
原始的1kGP资源的一个重要方面是,它被用作变量归因的参考面板,即,在稀疏的、基于阵列的样本中对未观察到的基因型进行统计推断,该样本基于从参考面板学习到的群体中通常一起遗传的变量的分组,这促进了大量全基因组关联研究(GWAS)。现在,随着原始资源的扩展,团队升级了参考归责面板,包括更多通过高覆盖率WGS和三个家族发现的变体。
NYGC的高级生物信息学科学家、该研究的共同第一作者Marta Byrska-Bishop博士解释说:“新的归因组包括了更多的位点,特别是许多更常见的INDELs和sv,因此扩大了GWAS可获得的变量的数量,考虑到非snv变异的大效应大小,这很可能有助于发现新的遗传关联,帮助确定致病变量。”
所有原始序列数据和变异调用集在测序完成后立即通过多个基因组数据存储库向公众发布,其中包括国际基因组样本资源(IGSR),该资源由欧洲分子生物学实验室(EMBL-EBI)的欧洲生物信息学研究所(European Bioinformatics Institute)的合著者维护。
“我们的目标是让这个公共资源成为未来群体遗传研究和方法发展的基准,”赵雪芳博士补充说,她是马萨诸塞州总医院基因组医学中心的博士后研究员,也是该研究的共同第一作者。
这些数据已经引起了遗传学和基因组学界的兴趣。由于1kGP样品完全开放获取的性质,这可能会持续数年,不像大多数新出现的WGS工作,1kGP样品是同意公开分发的遗传不受访问或使用限制的资料。
进一步探索