我们的大脑“时间戳”的声音来处理我们听到的词汇

我们的大脑“时间戳”的顺序传入的声音,让我们正确地处理我们听到的单词,一项新的研究显示,心理学和语言学的一个研究小组。它的发现,出现在杂志上自然通讯,神经系统功能的复杂性提供了新的视角。
“理解演讲,你的大脑需要准确地解释了语音的身份和他们的顺序说出正确识别单词就是说,”劳拉Gwilliams解释道,论文的第一作者,纽约大学博士生的研究现在加州大学的博士后研究员,旧金山。“我们展示了大脑如何实现这一壮举:不同的声音回应人口不同的神经。,每个声音都包含时间戳与多少时间已经因为它进入耳朵。这允许听众知道订单和声音的身份,有人说正确找出单词的人说的。”
当大脑在处理个人声音的作用的研究,有很多我们不知道如何管理快速听觉序列构成的演讲。额外的理解大脑的动态可能导致神经疾病处理,减少我们理解口语的能力。
在自然通讯研究中,科学家们旨在理解大脑如何处理语音的身份和顺序,鉴于他们发展得如此之快。这是很重要的,因为你的大脑需要准确地解释了语音的身份(例如,l-e-m-o-n)和秩序,他们说(例如,1-2-3-4-5)正确认识的单词(如。“柠檬”而不是“甜瓜”)。
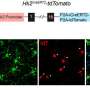
为此,他们记录了超过20的大脑活动人类被试——以英语speakers-while这些主题听两个小时的有声读物。具体地说,研究人员相关的受试者的大脑的活动与语音的属性,区分一个声音从另一个(例如。“m”和“n”)。
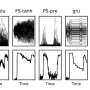
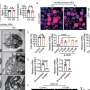
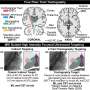
研究人员发现,大脑处理语言使用缓冲区,从而保持representation-i.e运行。time-stamping-of过去三个语音。结果还表明,大脑同时处理多个声音没有混合的身份,每一个声音,听觉皮层神经元之间传递信息。
“我们发现演讲声音启动一连串的神经元放电不同的地方在听觉皮层Gwilliams解释说:“谁会回到纽约大学的心理学系助理教授在2023年。“这意味着每个声音的语音信息词的k-a-t传递不同神经数量以可预测的方式,提供时间戳每个声音相对顺序。”
研究的其他作者是王Jean-Remi在巴黎高等师范学院,亚历克马兰士,纽约大学的语言学教授,纽约大学阿布扎比研究所的大卫Poeppel,纽约大学的心理系教授和恩斯特Struengmann神经科学研究所的董事总经理在法兰克福,德国。