血清学测试显示糖尿病和乳糜泻等疾病的病毒触发因素
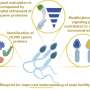
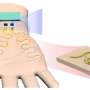
 is then used to design a library of peptides of a user-defined length that cover the supplied target sequences (green and blue bars). Next, amino acid sequences are informatically converted into DNA encodings, and constant regions (black segments) are added to each end. The corresponding DNA oligonucleotide library is prepared by massively parallel DNA synthesis and converted in bulk to a corresponding library of DNA-barcoded peptides (‘PepSeq probes’) by using in vitro transcription and translation and taking advantage of intramolecular coupling mediated by a tethered puromycin (P)-containing molecule. b, A library of PepSeq probes, prepared as in a, are then incubated with biological samples of interest, allowing antibodies to bind their cognate epitopes (binding indicated by the yellow halos). The antibodies are then captured onto protein-bound beads via their constant regions, unbound PepSeq probes are washed away and bound PepSeq probes are eluted. c, The DNA tags of eluted PepSeq probes are amplified by PCR, and the relative abundance of each probe is quantified by using high-throughput sequencing. Changes in relative abundance provide a semi-quantitative measure of cognate antibody abundance/affinity for each peptide in the design. Created with BioRender.com. Credit: <i>Nature Protocols</i> (2022). DOI: 10.1038/s41596-022-00766-8")
一种新的血清学测试不仅可以帮助人类准备和应对下一次大流行,而且在寻找糖尿病和乳糜泻等疾病的病毒触发因素方面也至关重要。
生物科学系和病原体与微生物组研究所(PMI)的助理教授Jason Ladner是PepSeq技术的领先创新者,该技术允许科学家一次测试抗体与数十万个蛋白质靶标的结合,而不是一次测试一个。当我们试图追踪一种传染性病毒,如冠状病毒,并找出如何应对它时,快速获得答案可能是生与死之间的答案。
在11月早些时候发表的一篇文章中详细介绍了该协议自然的协议.
这篇论文,“PepSeq:使用可定制的dna编码肽库进行高度多路复用血清学的完全体外平台”,描述了进行高度多路复用血清学分析的新方法,详细介绍了团队设计和合成定制PepSeq库的方法,以及如何使用这些库进行分析和解释数据。Ladner说,希望为世界各地的科学家提供一个路线图,让他们在自己的研究中使用该协议,使我们更接近一些主要传染病的答案。
这是重要的一步,因为人们对生物恐怖主义的担忧,人畜共患疾病下一次大流行离我们不远。了解这些病原体将有助于科学家开发疫苗,并追踪它们的运动和进化。
他说:“血清学检测对于诊断许多人类和动物感染非常重要。”“然而,传统的检测方法往往缺乏敏感性和/或特异性。我们的方法可以帮助确定在感染过程中哪些蛋白质最常刺激抗体反应,哪些表位对感兴趣的病原体是特异性的,而不是在相关病原体之间交叉反应。”
什么是PepSeq?
最基本的是,该协议允许科学家测试如何蛋白质的目标或抗原,一次能与成千上万的抗体结合。抗原是病原体(如病毒或细菌)的碎片,是宿主血液中抗体的目标。每一次新的感染都会产生新的抗体,这些抗体对特定抗原具有高度特异性,可以持续几个月甚至几年。因此,抗体有助于防止未来受到类似病原体的感染,但它们也提供了过去接触的记录。
那么,医学方面的一个大问题是,哪些抗体可以防止感染。这就是人类在2020年发现自己的地方——不知道身体需要开发哪些正确的抗体来应对COVID-19。这些信息是制造有效疫苗所必需的,未来还可以帮助开发疫苗接种方法,广泛预防SARS-CoV-2等冠状病毒,包括那些我们尚未识别的病毒。
一个更大的问题是确定需要哪些抗体来攻击病原体的抗原。这就是人类在2020年发现自己的地方——不知道身体需要开发哪些正确的抗体来应对COVID-19。研制有效疫苗需要这些信息。
PepSeq最初是由包括约翰·阿尔廷(John Altin)在内的团队开发的,他现在是TGen的研究员,Ladner的合作者和这项研究的合著者,它在两个关键方面对这一过程做出了贡献。首先,它使科学家能够同时评估大量不同抗原之间的抗体结合。因为抗体是宿主过去感染的证据,知道一个人有什么抗体可以提供线索,了解他们过去接触过什么病原体。这种方法允许研究人员通过测试已知的所有感染人类的病毒的过去感染的证据来广泛地探索接触历史。
“这可以帮助我们更好地了解传染病的流行病学,也使我们能够寻找非传染性疾病的潜在病毒触发因素,如糖尿病和糖尿病乳糜泻拉德纳说。
其次,PepSeq中使用的抗原是短肽,这意味着它们的长度通常不超过64个氨基酸。这意味着每次抗体与PepSeq抗原结合时,信号都是特定于特定蛋白质区域的,这使得Ladner和他的团队能够详细分析抗体反应。它有助于弄清楚病原体的哪些部分最常被抗体靶向,哪些抗体针对特定病原体(如导致COVID-19的新型冠状病毒),以及哪些抗体可以交叉识别(并潜在地交叉保护)密切相关的病原体,如可能导致普通感冒的冠状病毒。
他说:“特别是,我们对SARS-CoV-2和‘地方性’人类冠状病毒之间高度保守的几个表位非常感兴趣,这些冠状病毒已经感染人类几十年了,通常只会导致普通感冒。”“我们发现,抗体对这些表位的反应动态是不同的,针对这些区域的反应可以提供对冠状病毒的广泛保护。”
贯穿每一项检测的第三个关键因素是:PepSeq使这些检测能够快速运行,并且比其他检测的样本量要小得多——这很关键,因为这些样品通常是珍贵的,而且供应不足。
现在发生了什么?
这项研究为任何研究人员使用PepSeq提供了所需的信息。它还为他们在这个过程中所做的决定提供了基本原理,以便其他人可以在该技术的基础上进行开发。尽管这一方案具有创新性,但研究人员的目标是让其他人进一步创新。Ladner的团队正在领导生物信息学协议和定制软件包的开发,这些协议将创建PepSeq库,并允许解释通过协议收集的数据。
拉德纳说,从大局的角度来看,进行这类对话有助于该领域的整体进步。它有助于培养对过程和结果的信任。
他说:“即使PMI和TGen之外没有人最终使用PepSeq,我们也希望更广泛的科学界相信,结果是可靠的,而做到这一点的最佳方式是让整个过程透明。”“在这种类型的协议手稿中,我们可以更详细地介绍方法,而不是专注于使用PepSeq的特定研究项目的结果。”
拉德纳还在完善一种针对新样本类型的方案,包括人类唾液、尿液和吸血蚊子。他还使用PepSeq来更好地了解影响其他动物但不影响人类的病毒的分布和生态。这将使他的团队能够探索其他动物(如蝙蝠)的抗体反应性,从而证明哪些类型的病毒通常会感染这些宿主物种。
尽管这项研究的大部分是针对过程中事实调查部分的问题,但它应该为在未来的疫情爆发期间采取更有效的应对措施以及疫苗和病毒性疾病的治疗方法奠定基础。
Ladner说:“疫苗接种的主要目标之一是刺激保护性抗体反应的产生,PepSeq可以帮助我们了解抗体对疫苗接种的反应。”“PepSeq检测的结果肯定有助于制定与疫情准备和应对更直接相关的战略和方法。”