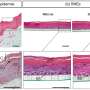
可以合成x射线解决医学影像数据的差距?

医学医生专攻罕见的疾病只能得到这么多学习的机会。缺乏多元化的医疗保健数据来训练学生在这些领域是一个关键的挑战。“当你在设置与稀缺的数据工作,你的表现与不同的更多的图片你看到更好的你成为“基督教Bluethgen说胸放射学家和斯坦福人工智能在医学与成像中心(爱実)博士后研究人员研究了罕见的肺疾病在过去七年。
当稳定的人工智能发布稳定的扩散,其text-to-image基础模型,8月向公众,Bluethgen有了一个想法:如果你可以把一个真正的需要与缓解医学创造美丽的图像从简单的文本提示吗?如果稳定的扩散可以创建医学图像精确的描述了临床上下文,它可以缓解训练数据的差距。
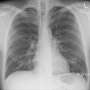
Bluethgen联手皮埃尔•Chambon斯坦福研究所的研究生计算和数学工程和机器学习爱実研究员设计研究,将寻求扩大稳定扩散的能力来生成最常见的一种医疗images-chest x射线。
在一起,他们发现一些额外的培训,通用潜在扩散模型在创建图像的任务执行得非常好辨认的人类肺部异常。这是一个有前途的突破,可能导致更广泛的研究,更好地了解罕见疾病,甚至可能发展新的治疗方案。
从通用到特定领域
直到现在,模型训练的基础自然图像和语言没有给定的领域特定任务时表现良好。医药和金融等专业领域有自己的术语,术语,和规则,不占一般训练数据集。但一个优势为团队的研究:提出了本身放射科医生总是准备一个详细的文字报告,描述了他们的研究结果在每个图像分析。通过添加这训练数据到稳定的扩散模型,研究小组希望模型能学会创建合成医学成像数据当提示有关医学关键词。
“我们不是第一个火车模型,胸部x光检查,但以前你必须用专用的数据集和计算能力付出很高的代价,“Chambon解释道。“这些障碍阻止很多重要的研究。我们想知道如果你能引导的方法和使用现有的开源地基模型只有轻微调整。”
三步过程
测试稳定扩散的能力,Bluethgen Chambon检查三个模型的子组件的架构:
- 变分autoencoder (VAE)压缩源图像和un-compresses生成的图像;
- 文本编码器,将自然语言提示转化为向量autoencoder可以理解;
- U-Net,功能的大脑图像生成过程(称为扩散)的潜在空间。
研究人员创建了一个数据集研究图像autoencoder和文本编码器组件。他们随机选择1000额射线照片的两个大,公共数据集,称为CheXpert和MIMIC-CXR。然后他们添加了5个人工图像正常胸部x射线和5个图片中清晰可见异常(在这种情况下,组织之间的液体积聚,称为胸腔积液)。这些图片是搭配一组简单的文本提示用于测试各种微调的组件的方法。最后,他们把一个样本的100万通用文本提示laion - 400 m公开数据集(一个大规模,non-curated组的图像文字对设计模型训练和广泛的研究目的)。
这就是他们问,发现,在一个较高的水平:
文本编码器:使用剪辑,一般域从开放的人工智能神经网络连接文本和图像,可以给出的模型生成有意义的结果当文本提示如“胸腔积液”是特定于领域的放射学吗?答案是——文本编码器本身提供足够的上下文U-Net创建医学上精确的图像。
VAE:稳定扩散autoencoder自然图像训练成功后,提出了医学图像un-compressed吗?再次,结果是肯定的。“一些注释的原始图像有炒,“Bluethgen说,“它并不完美,但采用的方法,我们决定国旗作为未来勘探的机会。”
U-Net:考虑到其他两个的开箱即用的功能组件,可以U-Net创建图像解剖学上正确的异常,并代表正确的设置根据提示?在这种情况下,Bluethgen和Chambon结束需要一些额外的微调。“在第一次尝试,原U-Net不知道如何生成医学图像,“Chambon报告。“但是一些额外的培训,我们可以得到有用的东西。”
的是什么
试验后提示和基准测试他们的努力使用定量质量指标和定性radiologist-driven评估,学者们发现他们表现最好的模型可能是习惯于插入一个逼真异常合成放射学图像,同时保持一个95%的准确率上深度学习模型训练的分类图像基于异常。
在后续工作,Chambon Bluethgen扩大训练努力,使用成千上万的胸部x光和相应的报告。由此产生的模型(称为伦琴,伦琴的混合和发电机),11月23日宣布,可以创建CXR图像与更高的保真度和多样性,增加和赠款更细粒度的控制imagefeatures像的大小和偏重结果通过自然语言文本提示。(这里的预印本可用。)
虽然这项工作建立在先前的研究,这是第一的胸看潜伏扩散模型成像,以及第一个探索新的稳定扩散模型生成医学图像。诚然,一些局限性浮出水面之际,团队反思的方法:
- 测量的临床准确性生成的图像是困难的,因为标准指标不捕捉有用的图像,因此,研究人员增加了一个训练有素的放射科医师的定性评估。
- 他们看到一个多样性的缺失产生的图像调整模型。这是由于相对较少的样本用于条件和训练U-Net域。
- 最后,进一步训练使用的文本提示U-Net的放射学为研究创建用例被简化的单词,而不是逐字取自实际放射科医师报告。Bluethgen和Chambon指出未来模型的整个或部分需要条件放射学报告。
此外,即使这个模型有一天非常成功,目前还不清楚如果医学研究人员可以合法的使用它。ob欧宝直播nba稳定扩散的开源许可协议目前医疗建议阻止用户生成图像或医疗结果的解释。
艺术或注释的x射线?
尽管目前的局限性,Bluethgen Chambon说他们很希奇的图像能够产生从这第一阶段的研究。“输入文本提示和回到你写下的一个高质量的图像是一个令人难以置信的新发明,任何情况下,“Bluethgen说。“这是令人兴奋的看看肺部x光图像重建。他们是现实的,不是卡通。”
向前移动,该小组计划探索多么强大latent-diffusion模型可以学习更广泛的异常,开始结合多个异常在一个单一的形象,并最终将研究扩展到其他类型的成像除了x射线和不同的身体部位。
“有很多潜在的在这方面的工作,“Chambon总结道。更好的医疗数据集,我们可以理解现代疾病和治疗病人的最佳方式。”
“适应Pretrained视觉语言基础模型医学成像领域背景”发表在预印本服务器上arXiv10月。
更多信息:皮埃尔Chambon et al,适应Pretrained视觉语言基础模型医学成像领域,arXiv(2022)。DOI: 10.48550 / arxiv.2210.04133