认知科学家开发了解释语言理解困难的新模型

长期以来,认知科学家一直试图理解是什么导致一些句子比另一些句子更难理解。研究人员认为,任何语言理解的解释都将受益于理解中的困难。
近年来,研究人员成功地开发了两个模型,解释了理解和制造句子的两种重要困难类型。虽然这些模型成功地预测了理解困难的特定模式,但它们的预测是有限的,并且与行为实验的结果不完全匹配。此外,直到最近,研究人员还无法将这两个模型整合成一个连贯的解释。
麻省理工学院大脑与认知科学系(BCS)的研究人员领导的一项新研究现在为语言理解困难提供了这样一个统一的解释。基于最近的进展机器学习,研究人员开发了一种模型,可以更好地预测个体创造和理解句子的难易程度。他们的研究结果最近发表在美国国家科学院院刊.
这篇论文的资深作者是BCS教授罗杰·列维(Roger Levy)和爱德华(泰德)·吉布森(Edward (Ted) Gibson)。主要作者是列维和吉布森以前的访问学生迈克尔·哈恩,他现在是萨尔大学的教授。第二作者是Richard Futrell,他以前也是Levy和Gibson的学生,现在是加州大学欧文分校的教授。
吉布森说:“这不仅是现有理解困难解释的放大版;“我们提供了一种新的潜在理论方法,可以更好地进行预测。”
研究人员在这两个现有模型的基础上建立了一个统一的理解困难的理论解释。这些老模型都指出了导致理解受挫的不同原因:预期困难和实践困难记忆检索.当一个句子不容易让我们预料到它接下来要说的单词时,我们就会经历期待的困难。我们经历困难内存检索当我们很难追踪一个含有复杂的结构例如:“律师不信任的医生惹恼了病人,这一事实令人惊讶。”
2020年,Futrell首先设计了一个统一这两个模型的理论。他认为,记忆的限制不仅影响含有嵌套从句的句子的检索,而且困扰着所有的语言理解;我们记忆的局限性不允许我们在语言理解过程中完美地表现句子上下文。
因此,根据这个统一的模型,记忆约束可以在预期中创造一个新的困难来源。我们可能很难预测一个句子中即将出现的单词,即使这个单词应该很容易从上下文中预测出来——如果句子上下文本身很难在记忆中保存的话。例如,考虑一个以“鲍勃扔了垃圾……”开头的句子,我们很容易想到最后一个词“出去”。但如果最后一个词之前的句子上下文更复杂,预期就会出现困难:“鲍勃把在厨房里放了几天的旧垃圾扔了出去。”
研究人员通过测量读者对不同理解任务做出反应所需的时间来量化理解难度。反应时间越长,对给定句子的理解就越有挑战性。先前实验的结果表明,Futrell的统一描述比两个旧模型更好地预测了读者的理解困难。但他的模型并没有识别出我们容易忘记句子的哪些部分——以及记忆检索的失败是如何混淆理解的。
哈恩的新研究填补了这些空白。在这篇新论文中认知科学家来自麻省理工学院的研究人员加入了Futrell,提出了一个基于新的连贯理论框架的增强模型。新模型识别并修正了Futrell统一解释中缺失的元素,并提供了新的微调预测,更好地匹配实证实验的结果。
在Futrell最初的模型中,研究人员首先认为,由于记忆的限制,我们的大脑不能完美地代表我们遇到的句子。但他们在此基础上增加了认知效率的理论原则。他们提出,大脑倾向于部署其有限的记忆资源,以优化其准确预测句子中新单词输入的能力。
这一概念导致了一些经验预测。根据一项重要的预测,读者通过依靠他们对统计上的单词共现的知识来弥补他们不完美的记忆表征,以便在脑海中隐式地重构他们所读到的句子。因此,包含稀有单词和短语的句子很难完美地记住,也更难预测即将出现的单词。因此,这样的句子通常更难以理解。
为了评估这一预测是否与我们的语言行为相匹配,研究人员使用了GPT-2,一种基于神经网络建模的AI自然语言工具。这种机器学习工具于2019年首次公开,使研究人员能够以一种以前不可能的方式在大规模文本数据上测试模型。但是GPT-2强大的语言建模能力也带来了一个问题:与人类相比,GPT-2完美的记忆完美地代表了它处理的非常长和复杂文本中的所有单词。
为了更准确地描述人类语言理解,研究人员添加了一个组件,模拟类似人类的内存资源限制——就像Futrell的原始模型一样——并使用机器学习技术来优化这些资源的使用方式——就像他们提出的新模型一样。最终的模型保留了GPT-2在大多数情况下准确预测单词的能力,但在单词和短语罕见组合的句子中显示出类似人类的故障。
吉布森说:“这是一个很好的例子,说明了现代机器学习工具如何帮助发展认知理论,以及我们对大脑如何工作的理解。”“即使在几年前,我们也不可能在这里进行这项研究。”
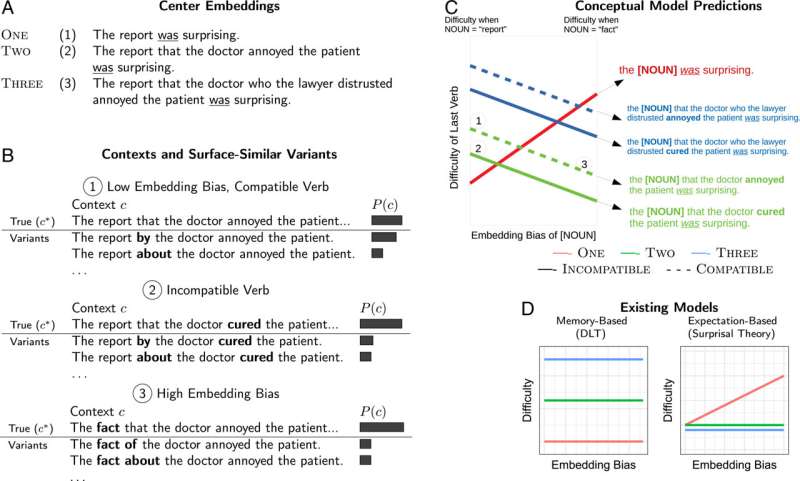
研究人员向机器学习模型输入了一组含有复杂嵌入从句的句子,例如,“律师不信任的医生惹恼了病人的报告令人惊讶。”然后,研究人员将这些句子的开头名词——如上面例子中的“报告”——替换为其他名词,每个名词都有可能出现在后面的从句中。
一些名词使它们被插入的句子更容易被人工智能程序“理解”。例如,当这些句子以常见的短语“the fact that”开始时,该模型能够更准确地预测它们如何结束,而不是以罕见的短语“the report that”开始时。
然后,研究人员开始通过对阅读类似句子的参与者进行实验来证实基于人工智能的结果。他们对理解任务的反应时间与模型预测的反应时间相似。吉布森说,当句子以‘report that’开头时,“人们往往会以一种扭曲的方式记住这个句子。”这种罕见的措辞进一步限制了他们的记忆,从而限制了他们的理解。
这些结果表明,新模型在预测人类如何处理语言方面优于现有模型。
该模型展示的另一个优势是它能够提供不同语言的不同预测。利维说:“以前的模型知道为什么某些语言结构,比如含有嵌入从句的句子,在记忆的限制下通常更难处理,但我们的新模型可以解释为什么相同的约束在不同的语言中表现不同。”
“例如,对于以德语为母语的人来说,带有中心从句的句子似乎比以英语为母语的人更容易理解,因为以德语为母语的人习惯阅读从句将动词推到句尾的句子。”
Levy认为,除了嵌入从句之外,还需要对模型进行进一步的研究,以确定导致句子表示不准确的原因。“我们还需要测试其他类型的‘困惑’。”与此同时,哈恩补充说,“这个模型可能会预测其他没有人想过的‘混乱’。我们现在正试图找到它们,看看它们是否会影响人类理解为预测”。
未来研究的另一个问题是,新模型是否会导致人们重新思考一长串专注于人类生存困难的研究句子整合:“许多研究人员强调了我们在脑海中重建语言结构的过程存在的困难,”利维说。“新的模型可能表明,这种困难与心理重建的过程无关句子而是一旦它们已经被构建起来,就能维持心理表征。一个很大的问题是,这是否是两件独立的事情。”
吉布森补充说,无论如何,“这种工作标志着这些问题研究的未来。”
本文转载自麻省理工学院新闻(web.mit.edu/newsoffice/),这是一个很受欢迎的网站,涵盖有关麻省理工学院研究、创新和教学的新闻。