公平的AI路线图:揭示医学成像偏差在人工智能模型
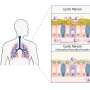
 has been recognized as a powerful tool in the field of medical imaging. However, these models can be subject to several biases, leading to inequities in how they benefit both doctors and patients. Understanding these biases and how to mitigate them is the first step towards a fair and trustworthy AI. Credit: MIDRC, midrc.org/bias-awareness-tool.")
人工智能和机器学习(AI /毫升)技术不断发现新的应用程序跨多个学科。医学也不例外,AI / ML被用于诊断、预后、风险评估和各种疾病的治疗反应评估。特别是,AI /毫升模型找到越来越多的应用在医学图像的分析。这包括x射线、计算机断层扫描和磁共振图像。成功实现的关键要求AI /毫升模型在医学成像是确保适当的设计、培训和使用。然而,在现实中是极具挑战性的开发人工智能/毫升模型适合所有成员的人口和可推广到所有的情况。
就像人类,AI /毫升模型可以有偏见,可能导致微分治疗医学上类似的病例。尽管相关的因素的引入这样的偏见,解决这些问题是很重要的,确保公平、公平、和信任在AI /毫升医学成像。这需要确定偏差的来源,可以存在于医疗成像AI /毫升和发展战略来缓解。未能这样做会导致微分有益于病人,加重医疗不公平的访问。
报道的《医学影像(JMI),一个专家小组从医学影像和数据资源中心(MIDRC)包括医学物理学家,AI /毫升研究人员、统计人员,医生,科学家从监管bodies-addressed这个问题。在这种综合报告,他们确定29的潜在来源偏见可能出现的五个关键步骤开发和实现医学影像AI /毫升从数据收集、数据准备和注释,模型开发、评估模型和部署模型,与许多确认偏见可能发生在多个步骤。偏见缓解策略进行了讨论,也可用的信息MIDRC网站。
偏差的主要来源之一在于数据收集。例如,采购图像从一个医院或从单一类型的扫描仪会导致偏见的数据收集。数据收集过程中也会产生偏见的差异如何处理特定的社会群体,在研究和在医疗系统作为一个整体。此外,数据可以成为过时的医学知识和实践发展。这就引入了时间偏差在AI /毫升模型训练等数据。
其他来源的偏见躺在数据准备和注释以及数据收集是密切相关的。在这一步中,偏见可以介绍基于数据标签之前被美联储AI /毫升模型进行训练。这种偏见可能源于个人偏见的注释器或疏忽有关数据本身是如何呈现给用户负责标签。
偏见也可以出现在模型开发基于AI /毫升模型本身是合理的和创建。一个例子是遗传的倾向,这发生在偏见AI /毫升的输出模型用于训练另一个模型。模型开发的其他偏见的例子包括目标人群的偏见造成的不平等的表示或源自历史环境,如社会和制度偏见导致歧视性做法。
模型评价也可以偏见的一个潜在来源。测试模型的性能,例如,可以通过引入偏见已经偏向为基准数据集或通过使用不恰当的统计模型。
最后,偏见也可以在部署期间出现的人工智能/毫升模型在实际环境中,主要从系统的用户。为例,介绍了偏见,当一个模型不用于预定的类别的图像或配置,或当用户变得过分依赖了自动化。
除了彻底识别和解释这些潜在的偏见的来源,缓解的团队建议可能的方法和最佳实践实现医学影像AI /毫升模型。因此,本文研究提供了有价值的见解,临床医生,公众在医学成像AI /毫升的局限性以及一个路线图的调整在不久的将来。这反过来又可以促进更公平和部署在未来医学成像AI /毫升模型。
更多信息:凯伦Drukker et al,对公平的人工智能医学图像分析:识别和缓解潜在的偏见的路线图从数据收集到模型部署,医学影像杂志(2023)。jmi.10.6.061104 DOI: 10.1117/1.