科学家创建模型来预测抑郁和焦虑使用人工智能和社交媒体

大学的研究人员在巴西圣保罗(USP)使用的是人工智能(AI)和Twitter,世界上最大的社交媒体平台,试图创建焦虑和抑郁的预测模型能够在未来临床诊断之前提供这些疾病的迹象。
这项研究报告发表在《华尔街日报》的一篇文章中语言资源和评价。
建设一个数据库,称为SetembroBR,是研究的第一步。名字指的是黄色的9月,每年自杀的认识和预防活动,这一事实数据收集研究在9月开始一天。
第二步是仍然在进步,但提供了一些初步结果,如的可能性只检测一个人是否可能患上抑郁症的基础上他们的社会媒体朋友和追随者,没有考虑到自己的帖子。
编制的数据库组包含相关的信息文本的语料库(葡萄牙)和3900名Twitter用户的关系网络报道他已被诊断出患有或治疗前的心理健康问题调查。语料库包括所有公共微博发布的这些用户单独(没有转发),总共约4700万这些简短的文本。
“首先,我们手动收集时间,分析微博约19000用户,相当于一个村庄的人口或小镇。然后,我们使用两个数据集,一个用于用户报告被诊断出患有一种心理健康问题和另一个随机选择的控制目的。我们想要区分抑郁症患者和一般人群,“说Ivandre Paraboni,最后文章的作者和USP艺术学院的教授,科学和人文学科(每个)。
研究还收集微博从朋友和追随者,根据观察,有心理健康问题的人倾向于遵循一定的账户,如论坛、影响力和名人公开承认他们的抑郁。“这些人相互吸引。他们有共同的利益,”Paraboni说,他是一个人工智能中心的研究员(C4AI)。
心理健康障碍,包括抑郁和焦虑,是不断增长的全球关注。世界卫生组织(世卫组织)估计的基础上,2021年的数据,3.8%的世界人口,或约2.8亿人受到抑郁症的影响。
谁也估计增长25%在全球普遍存在的这些心理健康问题COVID-19大流行期间。研究微博收集在此期间。
在最近的一次调查显示,巴西卫生部784000名参与者中,11.3%的人说他们被诊断患有抑郁症。大多数是女性。
根据先前的研究,心理健康问题往往反映在语言使用的患者。这一发现导致了相当数量的研究涉及到自然语言处理(NLP),重点是抑郁、焦虑和双相情感障碍等。然而,大多数这些研究分析英文文本和并不总是匹配大多数巴西人的形象。
模型
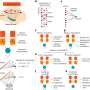
研究者预处理去除标签的语料库,url,表情符号和非标准字符,同时保持原始文本。然后,部署深度学习一种人工智能技术,教计算机处理数据的方式启发人类的大脑,创建四个文本分类器字嵌入(上下文相关的数学表示词与词之间的关系)使用模型基于双向编码器从变形金刚(BERT)表示,NLP的机器学习算法。这些模型对应于一个神经网络,学习背景和意义通过监测序列数据关系,比如单词一个句子中去。
训练的输入由样本中每个用户中随机选择的200条推讯。定义的参数执行5倍交叉验证的训练数据和计算的平均结果。
结论是伯特表现最好的预测抑郁和焦虑,有显著统计学差异和LogReg,下一个最好的选择。因为单词,完成句子的模型分析了序列,可以观察抑郁症患者,例如,倾向于写对象连接到自己,在第一个人使用动词和短语,以及死亡等主题,危机和心理学。
“抑郁症的迹象,可以发现在访问医生不一定一样的出现在社会媒体,“Paraboni说。“例如,使用第一人称单数代词我和我是非常明显的,而在心理学这被认为是一个典型的抑郁症的迹象。我们还观察到心脏的频繁使用emoji抑郁用户。这被广泛认为是亲情和爱情的象征,但也许心理学家还没有特征。”
收集到的文献都是匿名。“我们发表实际tweet和用户的名字。我们照顾,以确保学生参与项目没有访问用户数据,以保护人们的身份,”他说。
研究人员目前正在扩展数据库,改进计算技术和升级模型为了看看他们是否可以产生未来的工具在筛选潜在的患者使用心理健康问题并帮助家人和朋友的年轻人面临的风险抑郁症和焦虑。
巴西排名第三的国家之一,大多数消费社交媒体在世界上,根据Comscore的调查发表在3月初,印度和印尼,但背后的美国,墨西哥和阿根廷。它的1.315亿用户在线46小时平均一个月。使用最广泛的平台是YouTube、Facebook、Instagram, TikTok,葵和Twitter,最近改变了规则,开始对某些服务收费。
更多信息:韦斯利·拉莫斯多斯桑托斯et al, SetembroBR:社交媒体语料库为抑郁和焦虑障碍的预测,语言资源和评价(2023)。DOI: 10.1007 / s10579 - 022 - 09633 - 0